
웹을 다루는 대부분의 마케터가 유입 분석을 하고 있는데 유입 분석의 첫 단계는 무엇을 통해서 우리 웹사이트에 방문했는지 알아보는 것이다.
그럼 어디서 우리 웹사이트를 방문했는지 어떻게 알 수 있을까? 이때 필요한 것이 HTTP 리퍼러(HTTP Referer)인데 대부분의 유입 분석을 도와주는 도구는 HTTP 리퍼러 정보를 이용해 1차적으로 유입 정보를 수집한다.
리퍼러를 사용하면 마케터 입장에서도 웹사이트 방문자의 방문 의도를 더 심도 있게 알 수 있는데 이번 글에서는 바로 이 리퍼러에 대해 한 번 이야기하려고 한다.
URL의 구조
본격적으로 리퍼러를 다루기 전에 URL이 어떻게 구성되어 있는지 구조를 한 번 알아보고 시작하자.
| 속성 | 설명 |
|---|---|
| hostname | 도메인을 의미한다. |
| path(/) | 경로를 가리키며 대부분의 URL은 hostname과 path로 이루어져 있다. |
| query parameter(?) | key=value 형태로 이루어져 있으며 여러 개가 필요할 때 &로 구분한다. 우리에게 익숙한 UTM이 query parameter를 이용한 것이다. |
| ?(물음표) 뒤에 온다. | |
| fragment(#) | 해시 또는 앵커라고도 부른다. |
| 특정 ID를 링크로 걸거나 페이지의 state를 나타내기 위해 주로 사용한다. |
네이버 검색 결과의 URL
위 구조를 토대로 아래 네이버 검색 결과 주소를 한 번 뜯어보자.
https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=ogaeng
| 속성 | 값 |
|---|---|
| hostname | search.naver.com |
| path(/) | /search.naver |
| query parameter(?) | sm=top_hty |
| fbm=0 | |
| ie=utf8 | |
| query=ogaeng |
여기서 주목해야 할 정보는 query parameter인데 눈치가 있는 사람이라면 매개변수 한두 개 정도는 무엇을 뜻하는지 알아차렸을 것이다.
특히, query=ogaeng이 먼저 눈에 띄었을 텐데 query가 의미하는 건 검색할 때 입력한 검색어다.
그럼 sm=top_hty는 무엇을 의미할까? 이런 매개변수가 어떤 상황에서 변하는지 확인해보면 유추하는 것이 훨씬 수월해진다.
네이버 검색 결과 화면 우측에 있는 뉴스토픽 순위에 있는 토픽 중 하나를 눌러보자.
눌러보니 sm과 query 정보가 바뀌었다. query가 뜻하는 건 이미 알고 있으니 이제 sm이 무엇을 의미하는지 보이는가? sm은 검색 위치이다.
쇼핑몰 상세페이지의 URL
이번엔 쇼핑몰을 한 번 방문해보자 요즘 눈이 침침해 챙겨 먹고 있는 루테인 상품의 상세페이지 주소를 가져와봤다.
https://www.shopagh.com/goods/goods_view.php?goodsNo=1000000246
| 속성 | 값 |
|---|---|
| hostname | www.shopagh.com |
| path(/) | /good/goods_view.php |
| query parameter(?) | goodsNo=1000000246 |
이제 대충 감이 오는가? 눈여겨봐야 할 부분은 goodsNo이다. 이 매개변수가 바로 상품코드를 의미한다고 볼 수 있다. goodsNo의 값이 바뀌면 다른 상품의 상세페이지로 이동한다.
리퍼러(Referrer)
처음 방문하는 병원에서 진료를 위해 접수할 때 접수증을 유심히 본 적이 있는가? 항상 작성란 마지막 쯤엔 어디서 병원을 알게 됐는지 체크하거나 추천인의 이름을 적는 란이 있기 마련인데 이 것이 리퍼러와 같은 개념으로 이해하면 쉽다.
HTTP 리퍼러(HTTP Referer)는 웹 브라우저로 월드 와이드 웹을 서핑할 때, 하이퍼링크를 통해서 각각의 사이트로 방문시 남는 흔적
참조: https://developer.mozilla.org/ko/docs/Web/HTTP/Headers/Referer
그럼 우리나라에 존재하는 웹사이트의 대표적인 유입처인 네이버 검색 결과 페이지를 통해 리퍼러에 대해 조금 더 알아보자.
아래 URL은 PC 버전의 네이버 메인화면에서 ogaeng를 검색했을 때 등장하는 검색 결과의 URL이다.
https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=ogaeng
이때 검색 결과에 노출된 Ogaeng 블로그를 눌러 접속했다면 Ogaeng 블로그의 리퍼러는 위 URL이 된다.
그런데 앞에 있던 웹페이지의 주소가 기억나지 않는다면 리퍼러를 확인하는 방법은 없을까?
리퍼러를 확인하는 방법은 간단하다. 크롬 등의 브라우저에서 개발자 도구를 연다(크롬 기준 단축키: F12 혹은 cmd+alt+i) 그리고 Console 탭에 들어간 다음 이렇게 입력한다.
document.referrer;
그럼 현재 웹사이트의 리퍼러가 콘솔에 출력된다.
달라지는 리퍼러 정보
그럼 우리 웹사이트에 접속하기 바로 직전에 있던 웹사이트의 주소대로 리퍼러가 수집될까? 대부분 그렇지만 항상 그렇지마는 않다. 그 예로 우리가 흔히 방문하는 네이버 블로그 포스트 주소를 한 번 살펴보자.
블로그 글 본문에 링크가 있고, 그 링크를 눌러 우리 웹사이트에 접속했다고 생각해보자.
그럼 우리가 직접 눈으로 확인한 https://blog.naver.com/네이버아이디/글번호 의 형태로 리퍼러가 들어있어야 한다.
그런데, Console을 열어 document.referrer; 라고 입력해보니 아래와 같은 리퍼러 값을 보여준다.
https://blog.naver.com/PostView.nhn?blogId=네이버아이디&logNo=글번호&redirect=Dlog&widgetTypeCall=true
비슷한 듯하면서 또 다르다.
그럼 많은 마케터가 사용하는 구글 애널리틱스의 화면을 한 번 보자.
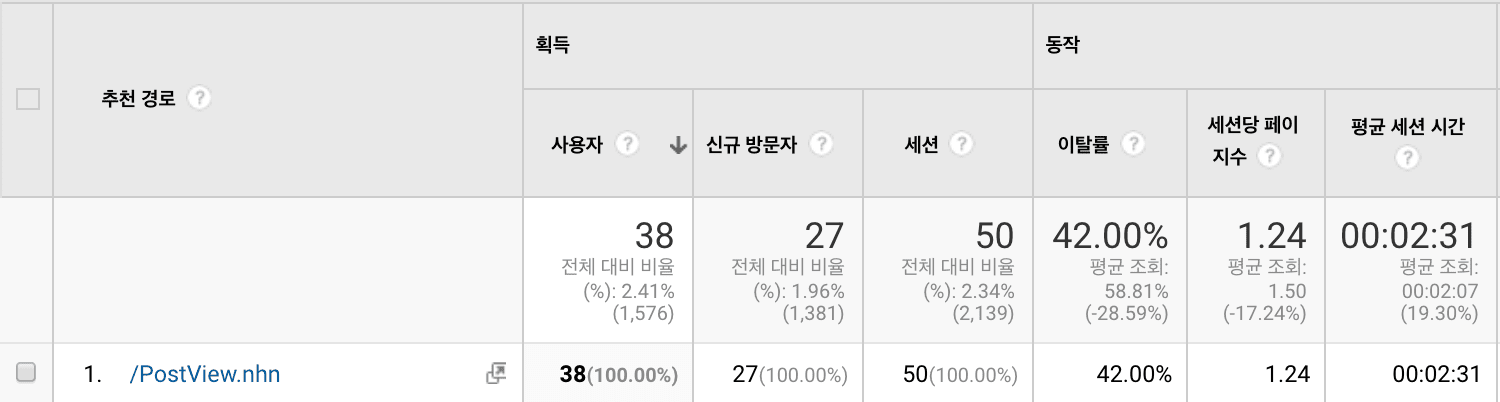
PC 버전 네이버 블로그에서 유입된 세션의 경로를 보면 위 이미지처럼 /PostView.nhn 이라고 나오는 걸 볼 수 있다. 위에서 본 리퍼러의 Path의 값이다. 더 자세한 값이 필요하다면 물음표(?) 뒤에 있는 query parameter의 값을 확인해야 한다. 이 전에 작성한 글을 보면 어떻게 query parameter 정보를 수집하고 구글 애널리틱스에 적용하는지 알 수 있다.
개인 정보 보호를 위한 리퍼러 정보 삭제
네이버처럼 리퍼러 정보가 그대로 혹은 변경돼서 들어오는 곳이 있지만 개인 정보 보호를 위해 리퍼러 정보를 삭제하는 곳도 있다. 대표적인 곳으로 페이스북과 구글이 있는데 먼저 페이스북의 포스트 URL 구조를 살펴보자.
https://www.facebook.com/사용자 ID/posts/글번호
페이스북 포스트에 삽입된 링크를 타고 우리 웹사이트에 접속하면 위와 같은 형태의 리퍼러 정보가 있어야 하지만 이상하게도 다른 정보가 모두 지워진 https://www.facebook.com/로 리퍼러가 들어오는 걸 볼 수 있다.
그럼 구글은 어떨까? 구글 검색 결과에 노출된 우리 웹사이트를 눌러 접속하면 검색 결과의 URL의 많은 정보가 지워진 https://www.google.com/로 리퍼러가 들어온다.
바로 이것이 구글 애널리틱스 등에서 유입 정보를 볼 때 google / organic에 키워드 정보가 없는 이유이다.(물론 서치 콘솔이 있지만 이건 다른 이야기니 패스)
마무리
이제 리퍼러가 무엇인지 간단하게 알았으니 심심할 때마다 개발자 도구의 Console을 열어 document.referrer;를 쳐보고 어떤 형태의 리퍼러가 들어오는지 확인하자.
그리고 우리 웹사이트의 방문자가 어떤 의도와 방법으로 우리 웹사이트에 접속했는지 자세히 뜯어보자. 뜯어보고 좋은 분석 방법을 찾았다면 혼자만 알지 말고 다른 사람과 공유하는 문화가 생기길 바란다.


